鱼和熊掌系列(2): ROS2的python可以变快吗
PUBLIC上次讨论了鱼和熊掌我要兼得:ROS2适合量产吗,基本回答了ROS2经过仔细调整之后,是不是可以性能很高。
是的,3.8%单核,在地瓜X5平台。
当时还是漏掉了一些东西,比如重要的,https://github.com/UniflexAI/tinynav 基本是用python的。
那么问题就是:
可以偷懒,在量产系统用中,用ROS2 python node吗。
先说结论:可以很接近,但是依旧有明显差距。
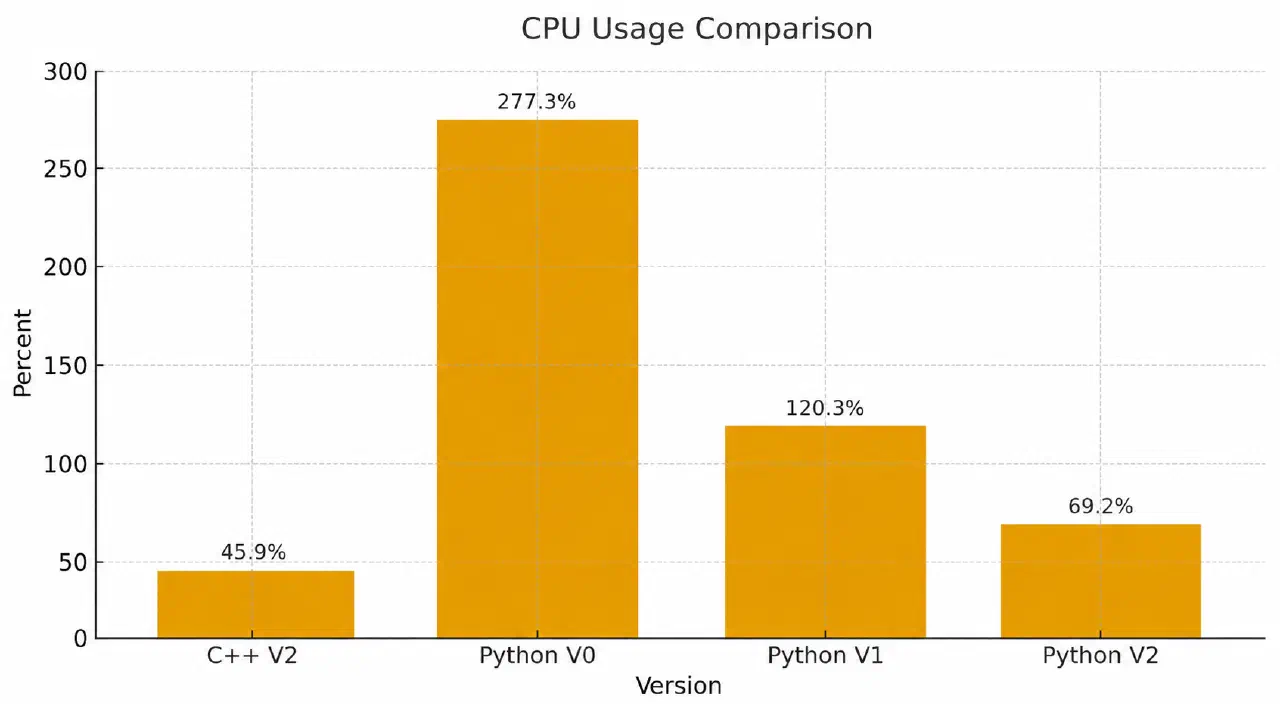
选一个对比的版本45.9%
鱼和熊掌我要兼得:ROS2适合量产吗中,到了v5是性能最高的,但是也不得不承认,可能也牺牲了一些易用性了。
其中一个大的变化就是在V2的时候,把整个system放到了single process,利用了这种情况下的一些优化,做到了16%。
如果从关爱自己的角度,我很乐意用16.0-3.8%的差异,换取更好的可读性。
对于今天要回答的问题,可能还是用多process结构更合适,那么baseline还是选择在V2版本了。
python的V0版本 277.3%
================================================================
CPU utilization summary (% of one CPU, 10s window)
================================================================
package node cpu
-------- ------------------ ----------
py perception_node 95.0%
py camera_node 19.6%
py imu_node 53.1%
py planning_node 21.4%
py control_node 88.2%
py all 277.3%
尴尬的数字。
不过结果确实是这样。
可以观察一下,其中 perception_node , imu_node 和 control_node 都异常的高。
他们的特点是什么。
都有200hz的输入。
经过搜索,这是一个ROS2长久的症结,rclpy面对高频msg的处理极其低效。
EventExecutor 由iRobot提出,现在可以在jazzy之后的版本使用。
现在也正在推进在下一个版本中作为默认的executor。
V1 EventExecutor 120.3%
================================================================
CPU utilization summary (% of one CPU, 10s window)
================================================================
package node cpu
-------- ------------------ ----------
py perception_node 48.4%
py camera_node 15.7%
py imu_node 16.1%
py planning_node 14.4%
py control_node 25.7%
py all 120.3%
简简单单。
继续分析呢。接下来就要涉及到rclpy层的实现,以及实际的DDS层了。
有一个很好用的工具。ros2_tracing可以帮助。
以720p为例,分析之后可以得到基本延迟在6ms,包括从publish到callback。
那么其中,publish占2ms,rmw_publish -> rmw_take占2ms,callback占1ms。
而且这三部分,都是随着图像变大而变慢,可以说,基本可以锁定是memory copy的问题。
那么,我们搜ros2 zero-copy,网页说我们要换cycloneDDS+iceoryx。
那么是不是这样呢。
我觉得工程师做分析的时候,不要迷恋名词:“我用了zero copy”,“我用了neon”。就能变快么。
先想一下memory copy可能发生在什么地方。我总结了一下:
numpy
→ Python Image.data
→ C ros_message uint8[]
→ CDR serialization buffer / DDS writer cache
→ DDS transport buffer / SHM segment
→ DDS reader cache / serialized buffer
→ deserialize 到 C ros_message uint8[]
→ Python Image.data
→ numpy view/copy
啊,原来有这么多地方。其实FastRTPS已经是默认用shm transport了。 但是关键是,client开始用这个数据的时候,并不是从DDS申请的内存啊。所以还是无法避免copy。 如果真的想全程zero copy需要搭配更多的API使用,包括Loaned Messages和Data-sharing。不在本文范畴。
下一步,是不是可以试着打开python的zero-copy。我想了很久,没有找到很好的办法。
但是我找到一个可以接受的办法。
V2 SHMImagePub/Sub 69.2%
求人不如求己。
如果在现在rclpy上去加Loaned Messages感觉不是一天两天的工作量,更不要说上次给message_filters提pr经历的冗长review了。
先hack一下,我们直接自己去维护shm好了。
关键的代码如下:
sender:
class SHMImagePublisher:
def __init__(self, node, topic, *, width, height, encoding="mono8", slots=8, shm_name=None, qos_profile=10):
self.shm = shared_memory.SharedMemory(name=self.shm_name, create=True, size=self.shm_size)
self.buffer = self.shm.buf
def publish(self, image, header=None):
arr = np.asarray(image, dtype=self.dtype)
self.buffer[payload_offset:payload_offset + self.payload_size] = arr.view(np.uint8).reshape(-1)
receiver:
class SHMImageSubscriber:
def __init__(self):
self.subscription = node.create_subscription(ShmImage, topic, self._on_msg, qos_profile)
def _on_msg(self, msg):
shm = self._get_shm(msg.shm_name)
dtype, channels = dtype_for_encoding(msg.encoding)
shape = shape_for_image(msg.height, msg.width, channels)
slot_base = msg.slot_index * (_SLOT_HEADER_SIZE + msg.size)
state, seq, _timestamp_ns, size = _SLOT_HEADER.unpack_from(shm.buf, slot_base)
if state != _STATE_READY or seq != msg.seq or size != msg.size:
return
image = np.ndarray(shape, dtype=dtype, buffer=shm.buf, offset=msg.offset)
self.callback(SHMImageSample(header=msg.header, image=image, msg=msg))
唉,很恶心的代码,但是确实有效果。
================================================================
CPU utilization summary (% of one CPU, 10s window)
================================================================
package node cpu
-------- ------------------ ----------
shm_py perception_node 26.1%
shm_py camera_node 4.0%
shm_py imu_node 12.8%
shm_py planning_node 3.7%
shm_py control_node 22.6%
shm_py all 69.2%
总结
就好像在SLAM中的时间检验奖中说的,读代码,真的是学东西,比看论文学东西好多了。
不可避免,在论文或者说PR中,“用了zero copy所以更快”“端到端,所以更智能”“从头写ROS解决性能问题”是更好理解的。
如果说,把各个模块都扣细去写,都不是很适合传唱的做法。
不管ROS2量产性这个话题的结论怎么样吧,我感谢这个community,感谢iRobot/Apex.ai这样的公司,感谢现在ros2的维护者。
不过说回来,量产的时候,我还是会优先考虑cpp的,哈哈哈。