一个使用体验很好的GPU云:vast.ai
PUBLIC起点是,自己有时候想做一点简单的实验,需要一个云上的GPU。
找了一圈,发现vast.ai的使用方式感觉非常惊艳,从2C消费电子的视角来看,使用体验很好。
在工作中也用了一段时间了,所以想描述一下我是怎么使用vast.ai的,为什么我喜欢使用它。
简单地说:vast.ai是一个2C的“众筹”云。买GPU的可以是独立消费者,卖GPU的也是独立消费者。
插一句,当说到2C的时候,心里在想什么。
我想到的就是,买家下单的时候,不需要“联系”商家,只是和网站下单即可。不要打电话,不要留邮箱,不要签合同,付款即可。
所以vast.ai并不是很“好”,只是很“方便”。最明显的限制是,只能买到单机,即使是能选到8卡B200/5090,也只是单机,可能对于现在很多人来说,已经不够用了。
然后就是不知道什么时候,大家会比较热情地训练网络,有一些卡就租不到了。
先把局限说在前面吧。
Get Started
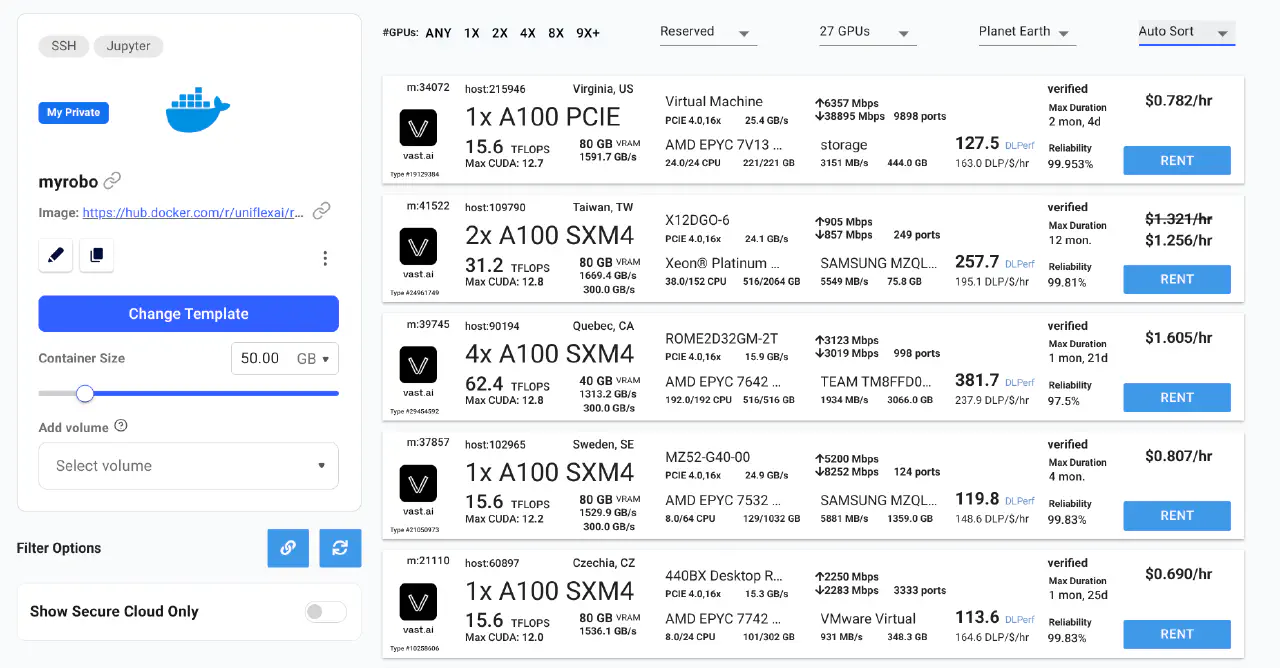
这就是一个典型的租赁页面,选择你想要的卡,指定需要的空间,然后就会建立一个实例。
根据我的工作流,总共需要这么几步:
- 搜索和创建实例
- 上传正在开发的github仓库的deploy key
- 上传自己笔记本里面的公钥
- mount 云端的目录到本地,方便看看图片什么的。
这里就有一个很好的工具可以用了:vastai CLI。这个cli工具很慷慨的返回了raw JSON的结果,基于它,我写了一个自己用的工具lazyvast:
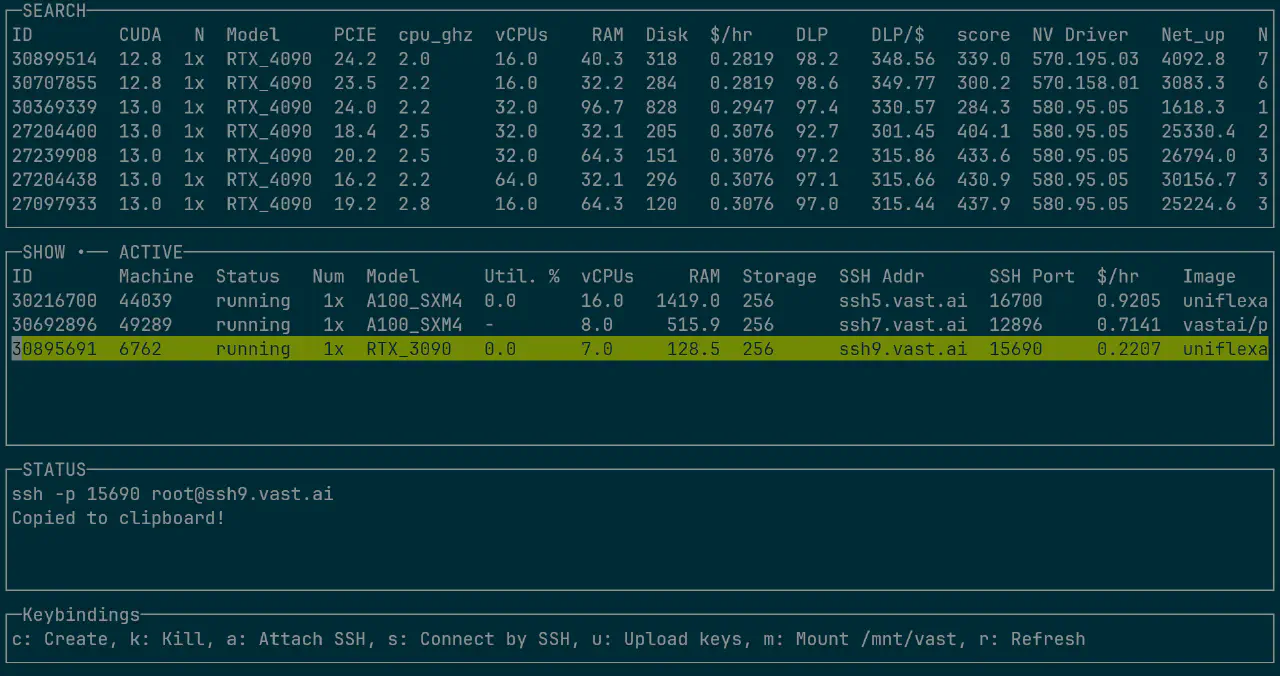
里面封装了一些我常用的命令。
维护一个常用的docker image
vast.ai整体上是提供一个Container给用户。
所以如果类似 docker pull pytorch/pytorch:2.10.0-cuda13.0-cudnn9-runtime 就够用了,就可以直接选这个镜像来用。
平常我是用devcontainer作为开发入口,所以维护了自己常用的一个镜像,也推送在docker hub里面了,这个时候也是可以直接用的。
如果需要一个私有的镜像,可以用docker hub里面private repo,加上Docker Access Token的方法来使用:

数据怎么办
vast.ai并不预设有很大的数据(我瞎猜的,主要是因为存储空间的价格好像都比GPU更贵了)。
所以我有两种常用的做法:
把数据集整理好,存在s3上,我常用的是BackBlaze。
这个平台很有意思,基本不收存储费,只收流量费。
这里提一下,选gpu的时候,最好选上网络带宽>5000Mbps的,这样从s3下载,基本可以做到100MB/s的速度。
不过我的数据集本来也不大,在这种速度下,10-20分钟就下载结束了,可以接受。
推荐一套比较快的rclone参数:
rclone sync backblaze:src dst \ --transfers=32 \ --checkers=32 \ --buffer-size=32M \ --fast-list \ --multi-thread-streams=32 \ --progress --stats=5s --stats-one-line公开数据集直接放在huggingface上,用Streaming的方法去获取。这样其实用起来更方便,但是准备数据集比较麻烦。而且很多已经有的代码,不支持IterableDataset,就更头疼了。
在wandb的log里面,能很清楚的看到网络流量的使用:

你也可以像geohot一样自己写一个tiny s3:https://github.com/geohot/minikeyvalue
之前看到这个repo的时候,不知道他要干什么。。。
直到这次开始把GPU和数据通过网络去连接,才明白。
这个项目也是挺有意思的。完全就是简单的用多个nginx作为volume server,然后用一个简单的中心节点做负载均衡。
audit log
vastai show audit-logs 可以给详细的统计信息,Team中不同的member的使用量什么的,如果想搞也可以,不过也没必要吧,毕竟vastai相比正规军,已经便宜太多了。。。
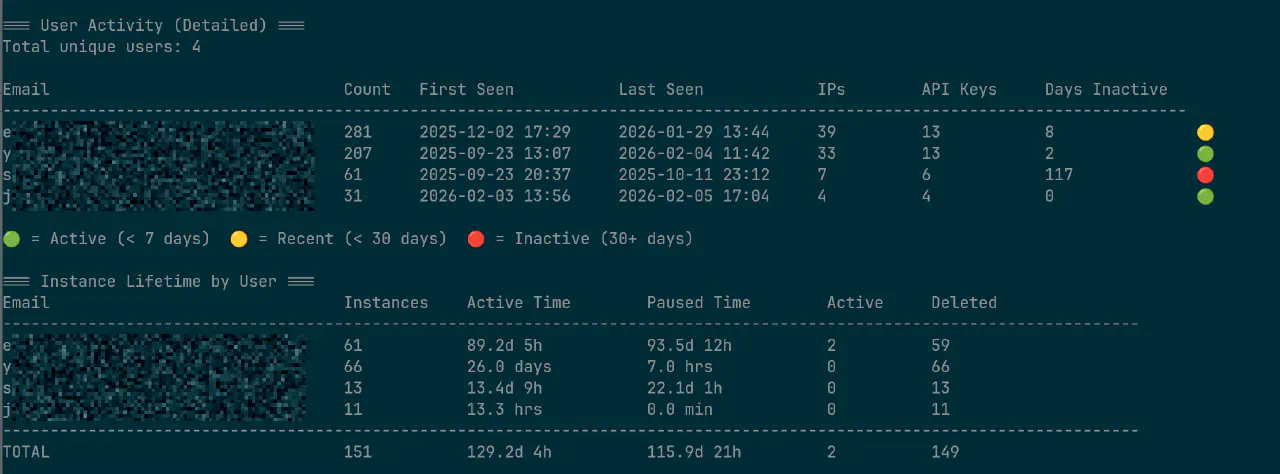
螺蛳壳里做道场
有一种在做体操的感觉。本身训练网络还是对工作比较重要吧。
至于怎么训练,还是只能归在“技巧”范围内,不足挂齿。
但是,拦不住这种东西实在是好玩啊。
如果你有更好玩的东西,let’s_have_a_talk。