E2E Self-Driving: 模仿可以产生智能吗?
e2e PUBLIC一条漂亮干净的路径,通往机器人的高可靠性终点。
从能吃下数据的尺度来排序:
Internet-Scale Data
无监督的训练掌握 常识
DINOv2变成de facto image encoder,VLM公认有“常识”,所以可以帮助action变成VLA
自动驾驶中用视频生成做模拟器,可以不只利用驾驶数据,更多普通数据可以包含更多自然的知识
人类示教数据
模仿学习的数据介绍 领域知识
Behavior Cloning + Video Generation-based Augmentation
更fancy的说法是world model,或者LeCun的JEPA
打分数据
在两个采样中,A比B更好,表达 偏好
用交替训练的方法,同时训练Reward Model,以及用这个Reward Model支持RL
有一个机器臂的工作用了这个方法,HiL-serl
看起来能统一地解决自动驾驶和机械臂的问题。
今天主要讨论模仿学习如何结合视频生成解决分布漂移的死结。
前情提要
(23.03.22) E2E Self-Driving in the Era of GPT
起点是对comma ai的分析。
- 为什么geohot可以对他自己的方案(一个非常粗放的端到端方案)如此有信心?
- 距离make the world a better place中提到的终极目标MTBF=10^7还差多远?
- 预训练模型(所谓的large model)对自动驾驶的帮助有多大,自动驾驶的Scaling Law存在吗?
- 如果存在,怎么训练,要花多少钱?
(24.05.23) E2E Self-Driving One-year Reflection
Wayve融资启发的一些想法。
- 端到端方法连在模拟器Carla的结果都普遍很差
- Large Model对自动驾驶的帮助依旧不是共识
- 用视频生成,对模仿学习的数据进行Augment的路径似乎开始清晰
- 视频生成牛了
- Imitation Learning的问题(Distribution Drift)变成最明显的障碍
更多的公开讨论
问题一:自动驾驶的scaling law存在吗
先说结论:在Open Loop中存在,在Close Loop中不存在。
或者说:模仿学习存在,但是模仿学习无法解决闭环控制。
(24.12.03) Preliminary Investigation into Data Scaling Laws for Imitation Learning-Based End-to-End Autonomous Driving https://arxiv.org/abs/2412.02689
- 理想汽车团队
- 数据量:4M sample,30k hours
- Close Loop,从2M samples开始平坦
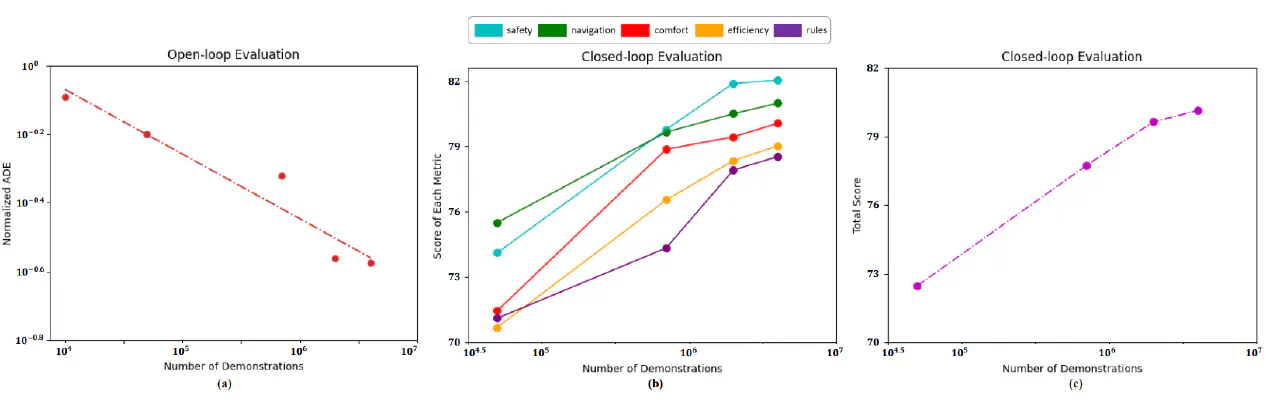
(25.04.06) Data Scaling Laws for End-to-End Autonomous Driving https://arxiv.org/abs/2504.04338
Nvidia团队
数据量:400k km,8k hours
Close Loop,从256 hours开始平坦
一通操作之后,实机部署,MTBF=24.41km
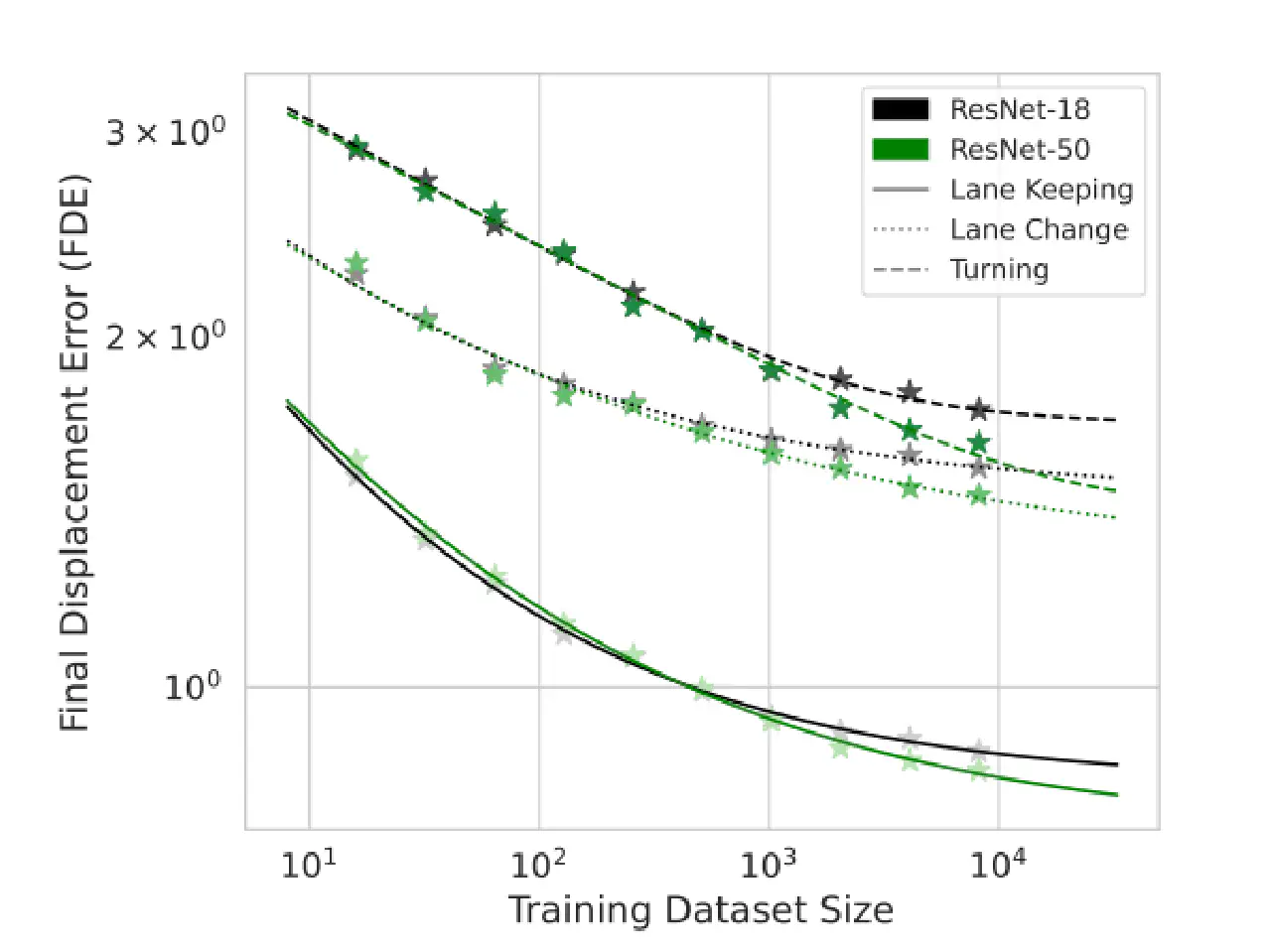
问题二:视频生成怎么帮助解决Distribution Drift
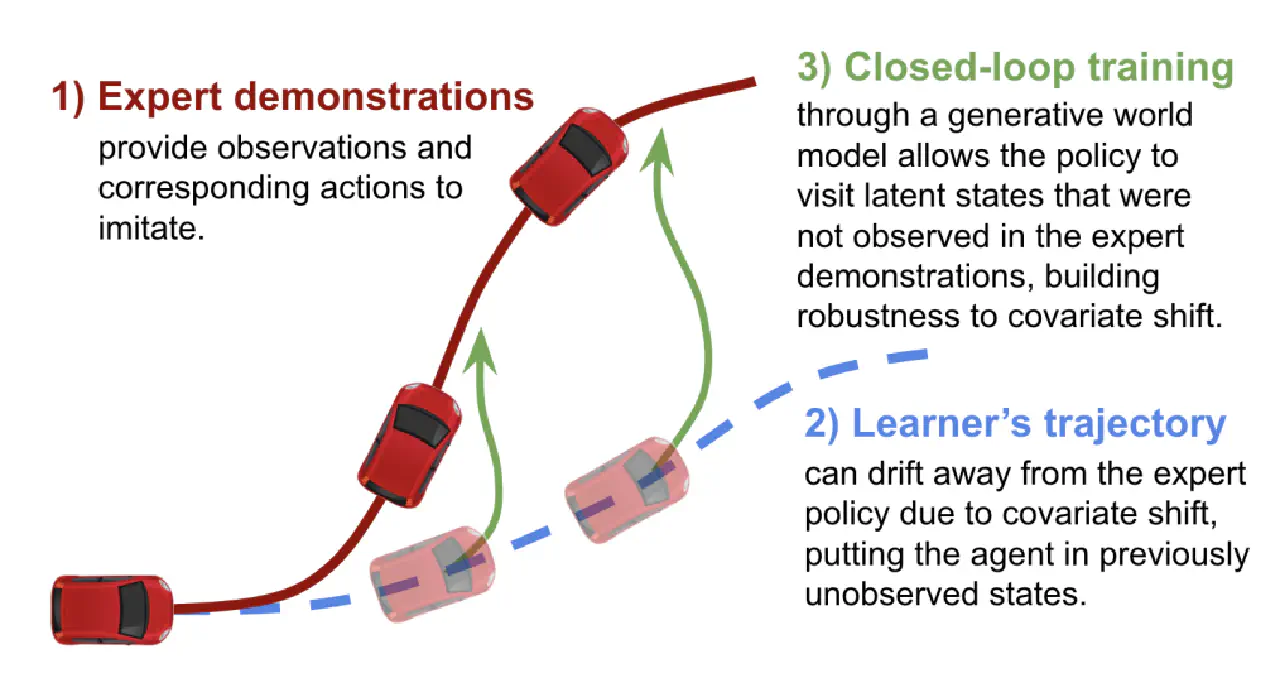
(2010.12.02) A reduction of imitation learning and structured prediction to no-regret online learning https://arxiv.org/abs/1011.0686
- 先驱工作DAgger
- 先部署,等车出问题了,人接管,再来把人接管的这段数据。
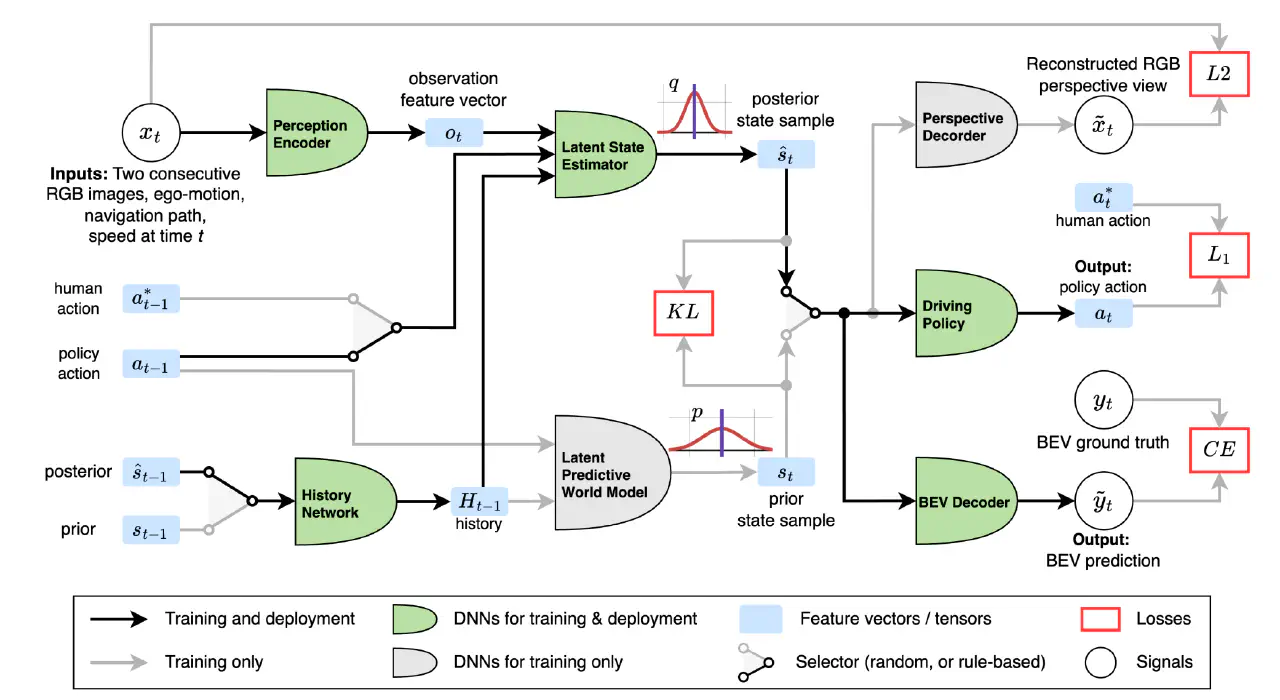
(24.09.25) Mitigating Covariate Shift in Imitation Learning for Autonomous Vehicles Using Latent Space Generative World Models https://arxiv.org/abs/2409.16663
- Nvidia团队
- 在Sensor Encoder+Action Encoder后面,接了一个Latent State Estimation采样去预测场景变化。这部分场景采样直接参与训练。 其中Action也从Policy或者模仿数据中随机选择来采样。
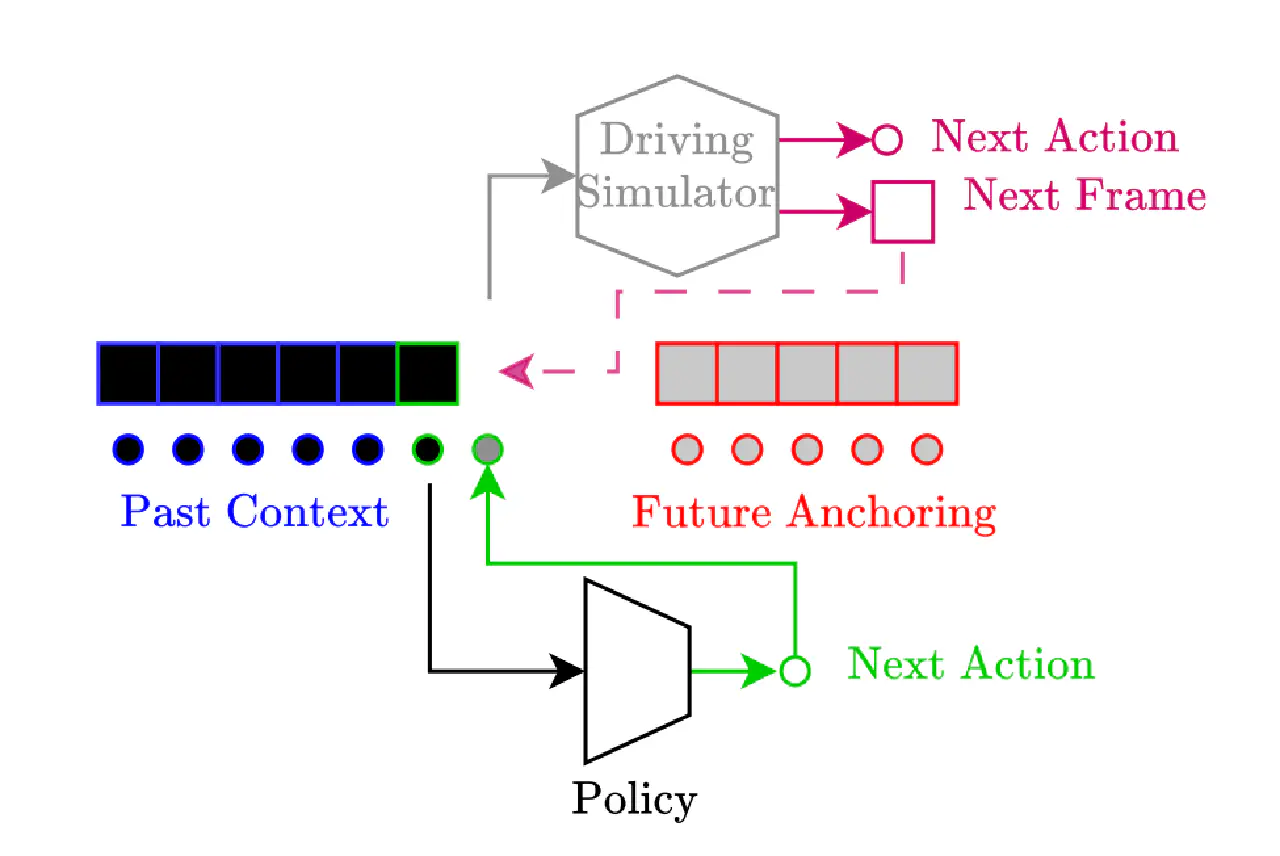
(25.04.27) Learning to Drive from a World Model https://arxiv.org/abs/2504.19077
- comma ai
- 更加像是一个模拟器视角
- 直接在Action上加噪音
- 有趣的结果是,对比了两种模拟器,一种是视频生成,一种是reprojective distortion。结果第一种表现只是略好。
| Reprojective | World Model | |
|---|---|---|
| Number of trips | 47,047 | 40,026 |
| Engaged % (time) | 27.63% | 29.92% |
| Engaged % (distance) | 48.10% | 52.49% |

结尾
暂时没想到,先写到这吧。