E2E Self-Driving in the Era of GPT
e2e PUBLIC DM大模型可以解决什么问题。
200公里?
抛开“L4做不成”的观点,讨论“L4哪里做不成”的事实。
Mobileye认为Robotaxi的质变点在于MTBF=10^7小时。那当前各家做到了什么水平呢:
小道消息:
- Pony的安全员:一两周一次
- 华为阿维塔,“200公里勉勉强强”
- 元戎 “比200公里低”
各家投入了200至1000名工程师,去克服这个问题,各个模块都尽可能地follow tesla,目前达到的水平就是如此。
是不是说明这条路很难scale up?无论是测试量,还是实际的MTBF,都需要考虑:证明MTBF是10^7,一定需要比10^7高一个数量级的测试量。
有没有绝对无法解决的问题?why_L4_is_hard
comma ai
这个23个人的公司做到了什么。
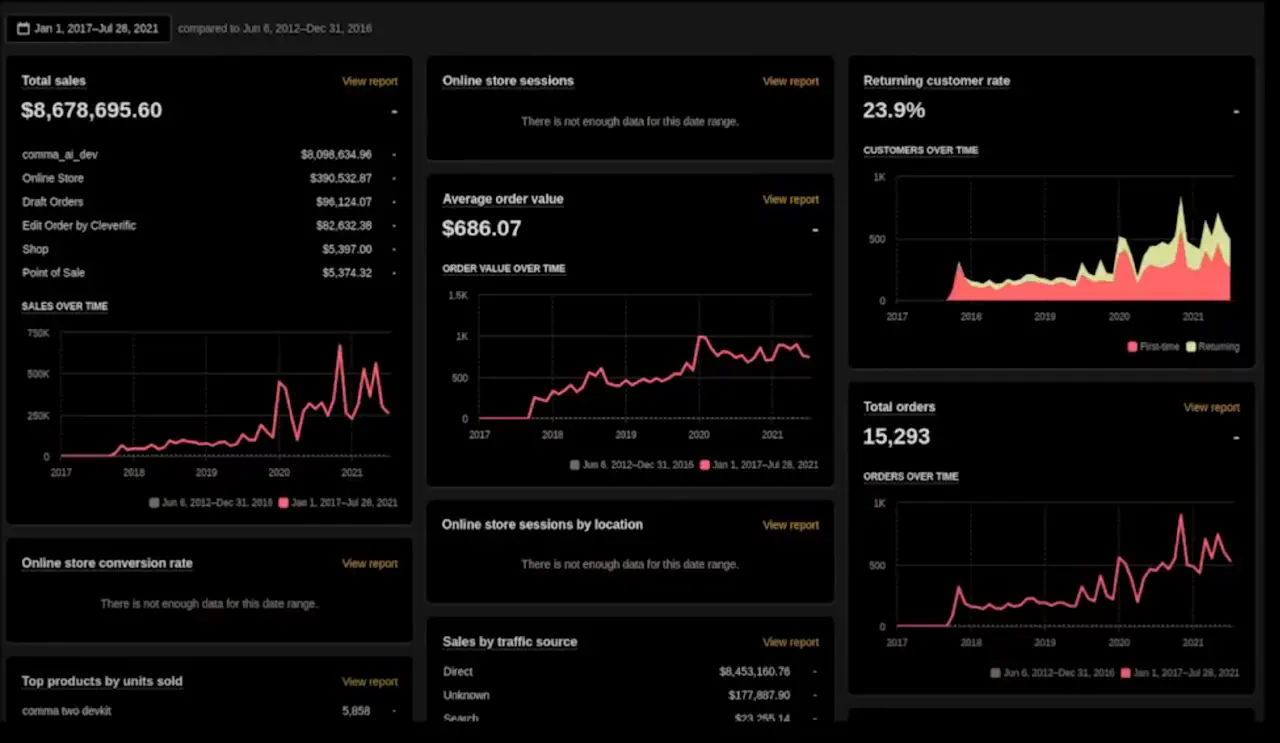
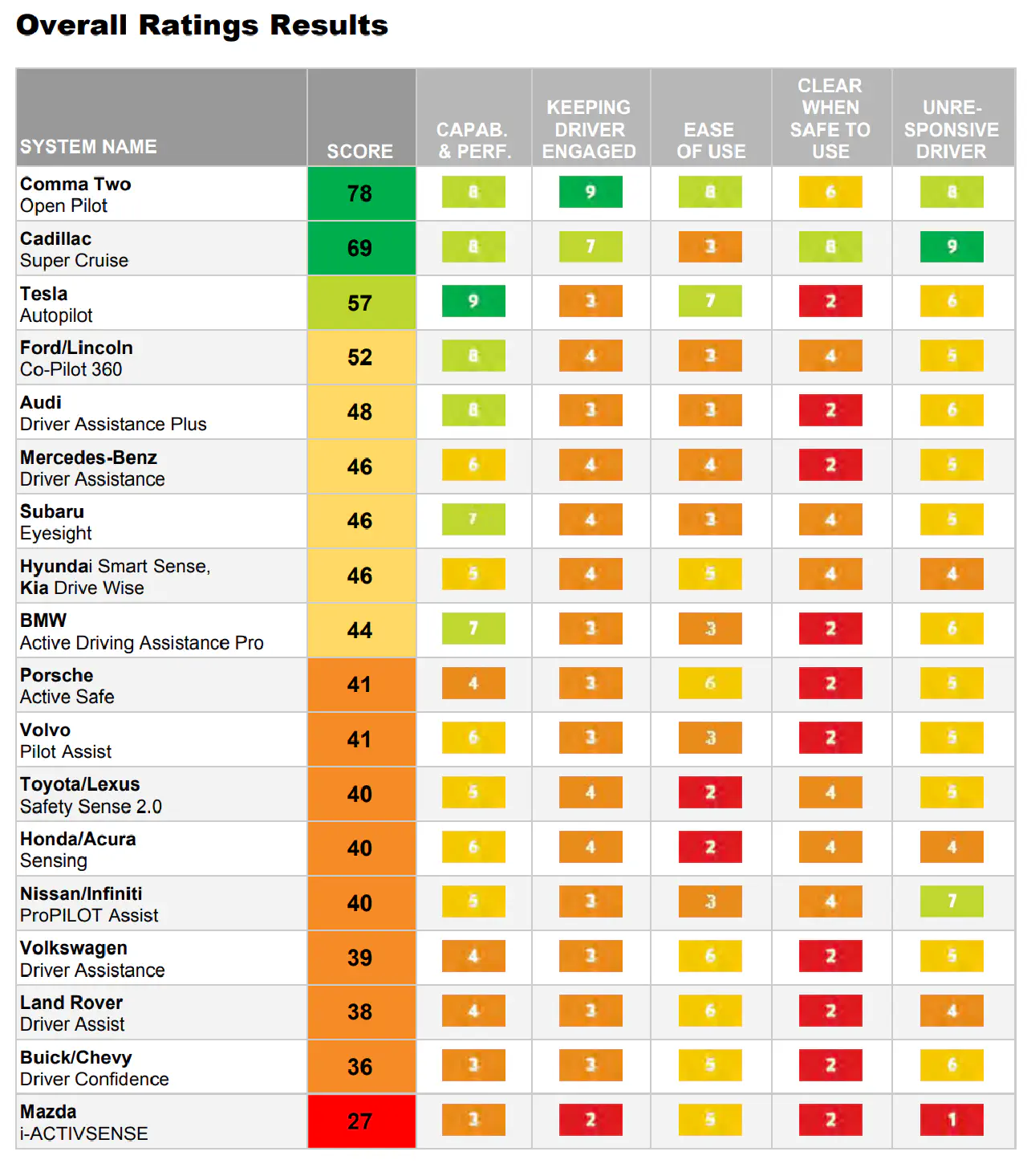
GeoHot是搞怪的还是认真做的。

具体来说是什么路径
(pretrain -> prediction/planning) + control/adapter
我们对prediction/planning + control,不陌生。
新的熵减来自,pre-trained large model。关键在于如何做到,以及做到之后有多大帮助(寻找scaling law)。
找pre-trained large model,约等于找数据在无标注下能利用的内在一致性是什么,比如:
- 语言是不是流畅是语言的内在一致性
- 同样的物体,在不同视角下看到的外表,在某种变换下是等价的
- 图片有内容,而不是乱码,通过遮挡一部分,我们也能知道里面画的是什么。
那么自动驾驶的一致性是什么。
一致性从哪里来
自动驾驶的一致性就是轨迹,特别的,是自己的车的轨迹。
这个信号相当于自动驾驶的world model,在预测自己的下一步的时候,要做很多内在的任务(哪里可以开,不能撞到什么,要不要减速)。
按analysis by synthesis的思路:如果模型可以对下一步去哪预测的很好,我们可以认为他 理解 了这个世界。
如何获取大量轨迹:可以用youtube上的行车记录仪数据。
别人想到这个想法之后,做过哪些工作
我们看看现有的工作是怎么解决轨迹来源:
| PPGeo1 | Shanghai AI lab | 用NN的Posenet出轨迹 | 精度不高,不能直接用,要再加一次投影误差 |
| ACO2 | zhou bolei | 用action做对比学习 | 粒度很粗 |
| UniAD3 | Shanghai AI lab | 模块化的网络结果,但是只用轨迹做监督 | 数据很少 |
| comma.ai | EKF(orb-slam, GPS) | 做的很早(提一嘴,live coding,11个小时搞定) |
这么看,comma ai才是那个做 难且正确 的事的人。
所以这像是两个圈子被隔绝开,能准备数据的人不会大规模训练,会大规模训练的人无法做轨迹的自动化标注(也就是建图)。
是不是很昂贵
大模型是少数人的特权吗。看看常见的工作需要多少GPU时。
| 数据规模 | GPU需求 | 备注 | |
|---|---|---|---|
| PPGeo1 | 48小时视频 | A100 x 64 | nuScenes中今年top1 |
| ACO2 | 8 GPU | ||
| Seg-everything4 | 11M 图片 | 256 A100 GPUS for 68 hours | 网红 |
| VideoMAE v25 | 240小时 64 A100 | 最大视觉预训练 |
GPU价格计算:
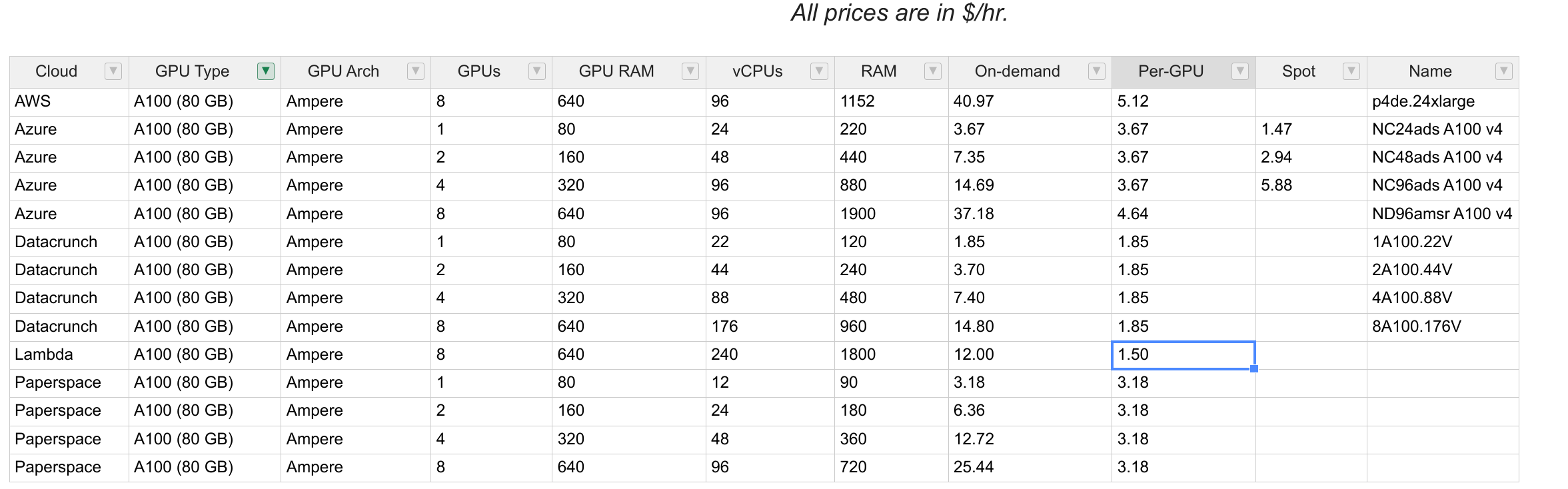
还是很贵的。明显的节省方向是:
- 实际只有last run需要最大资源
- 不一定train-from-scrach
- 不一定用A100 80G
还是挺贵的,对实验要求很高。
这样做距离L4差多少
UniAD汇报的结果:
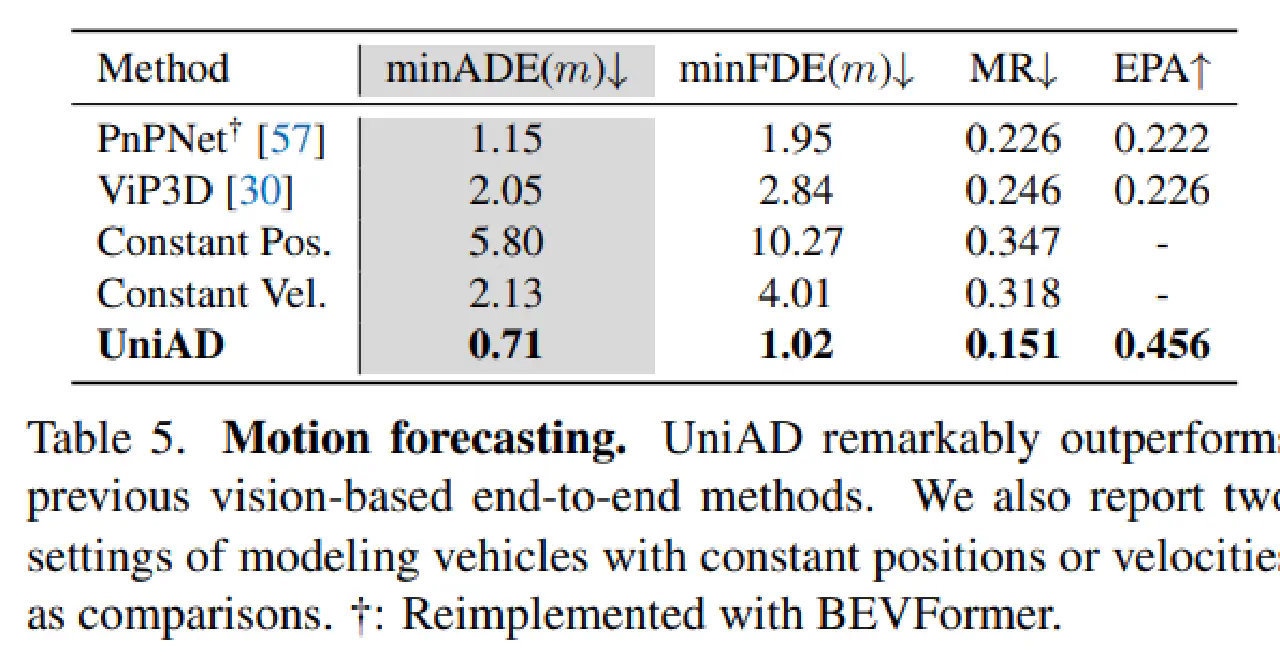
其中关注MR(missing rate预测轨迹和实际轨迹完全不一致)和minADE(轨迹的距离误差)。
粗略来看,15%的MR和0.7的minADE都不算好。
甚至作者自己短短的预览结果里都有明显的过度躲避
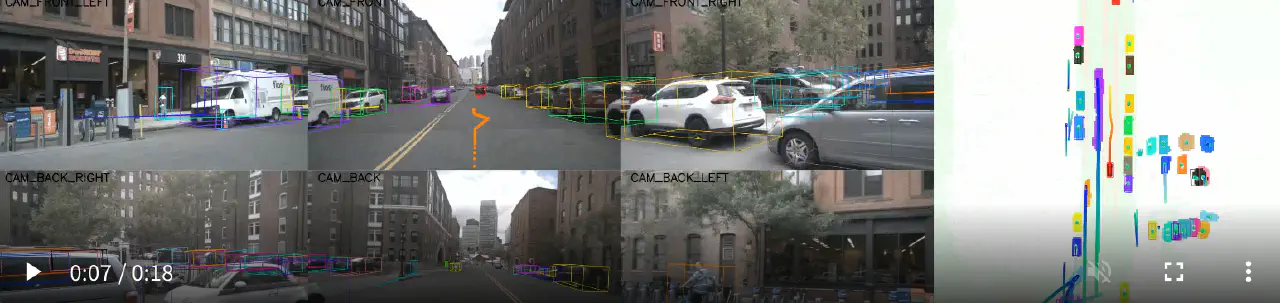
是不是对指标理解存在偏差?从youtube上众多comma three的结果来看,其表现都要比这更自然。
a key
Policy Pre-training for Autonomous Driving via Self-supervised Geometric Modeling ↩︎ ↩︎
Learning to Drive by Watching YouTube videos: Action-Conditioned Contrastive Policy Pretraining ↩︎ ↩︎
Planning-oriented Autonomous Driving ↩︎
Segment Anything ↩︎
VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking ↩︎